
Image taken from this video
Training a Cooperative AI Agent using Reinforcement Learning
Machine Learning agents can outperform humans in many tasks. One of humanity's strengths, however, is working together to achieve a shared goal. Is this powerful tool we call cooperation something that machines can learn from scratch?
Let's start out as simple as possible: What is cooperation?

Cooperation is the process of groups of organisms working or acting together for common, mutual, or some underlying benefit, as opposed to working in competition for selfish benefit. This is Wikipedia's definition of cooperation. If we ignore the "organism" part, we see that cooperation boils down to two or more entities joining forces to work towards a common goal. Let's also note here that the goal can also mean that each entity gains individual benefits, but needs a partner to achieve it. The essence is that cooperation describes the joint effort to achieve something.
Now that we understand the concept, how can we translate this into the world of computers? Well, actually, we know a pretty good digital way for us humans to test our cooperation capability: Playing multiplayer video games. So, for my Bachelor's thesis, I decided to create a range of arcade-style video games and set out to test whether Artificial Intelligence agents can successfully solve cooperative multiplayer tasks.
First of all, there was a fundamental decision to take: supervised, unsupervised, or reinforcement learning? Unsupervised learning can be crossed out first. It is used for detecting patterns and anomalies, which is not what we need here. Supervised learning, meaning training an AI agent by giving it vast amounts of data, certainly is a possibility. We could feed hours of pre-recorded multiplayer gameplay into a neural network and see if it later comes up with cooperative strategies. I, however, would argue that simply copying human cooperative behaviour does not prove that machines can learn to be cooperative. My method of choice was reinforcement learning. The agents play the game over and over again, only receiving a score for how well they did. In this scenario, they have to learn the concept of working together from scratch, enabling them to develop true cooperative behaviour.
Let's check out the games I used. Instead of using pre-made games like e.g. the digital adaption of Atari games, I decided to program my games from scratch. The reason for this was to have full control over the game physics, meaning I could easily adapt how the game works, how easy it is to solve and how cooperation is necessary to achieve high scores. I wanted to use games that could be played in both single- and multiplayer mode. This way, I could first train a single AI to tune the hyperparameters and then move on to the more complex multiplayer environment. Moreover, the games should be playable by humans as well. This is what I came up with:

The first game is a simple resource collection game. At the beginning of each episode, the map is covered in red blocks. The players each control a blue block that can move 1 step upwards, downwards, to the left or to the right in each round. Points are rewarded for each collected red block, the game ends after a fixed amount of turns and there are less turns then resources on the map, so the maximum number of points can only be achieved by collecting a resource in each turn.

I called the second game Catch. Each player navigates a platform (bottom of the frame) that can be moved left or right. In each episode, the same number of objects as there are platforms fall from the top of the frame to the bottom. As you can probably guess, the goal is to catch the objects by navigating the platform underneath them before they hit the ground. If there are multiple players, their platforms can move through each other's and every player can catch every object. This means that cooperation is necessary to succeed in a multiplayer game of Catch. One player has to catch one of the objects, the other one has to adapt which one is left to take care of.
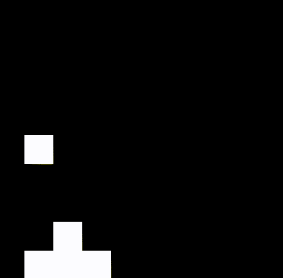
A two-player adaption of catch I developed is called Coopmobile Catch. Only one object falls down in each episode, but the players jointly operate a platform. Player 1 moves the wide bottom platform, Player two can adjust the position of a "basket" on top of the base platform. The players only score a point if they catch the object with the basket. This means that cooperation is strictly necessary. While the bottom player can take the upper one to the rough position of the object, the upper player has to do the fine-tuning in order to achieve the common goal of catching the object.
Next, I had to figure out the training. This was my first proper Machine Learning project at the time, so I did weeks
(maybe even months) of training and trying out different networks, training methods, parameters, and so on. For your
own good,
I'm only going to show you the successful runs here.
You can look up the technical details in my
publication on ResearchGate, but I will run you through
some basic concepts of my implementation here as well. The runs you can see in the following segments display the
training of fully connected deep neural networks. To make the networks' learning process as similar as possible to
one of humans, they receive
raw pixel values as input. Just like humans, they observe the game state only by an image, or "frame" of the video
game. After the networks process the current image by running the values through their neurons, they output a single
action for the current frame (e.g. move left).
This action is then applied, the game engine updates the game according to the internal physics, calculates the
reward for each player, and generates the next frame. The networks then learn by updating their strategy according
to the reward they just got. This loop goes on until the
episode is finished and starts again for the next episode.
Let's see how this training process looks like using some graphs from single-player game training:
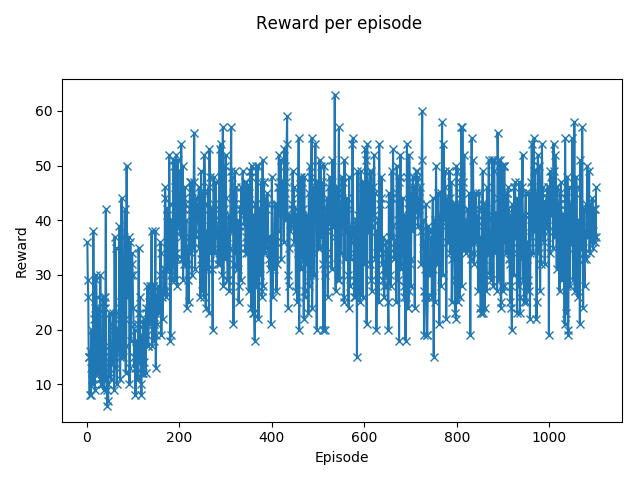
The above graph depicts the reward per episode for the player in the singleplayer resource collection game. You can see that, within the first 200 episodes of the game, the agent improves it's performance up to a level of averagely 40 collected resources per game. After episode 200, the performance oscillates heavily and the agent does not improve anymore. At the time, I couldn't figure out why and could not improve the performance any further, even after extensive experimentation with network size, structure, reward function and hyperparameters.
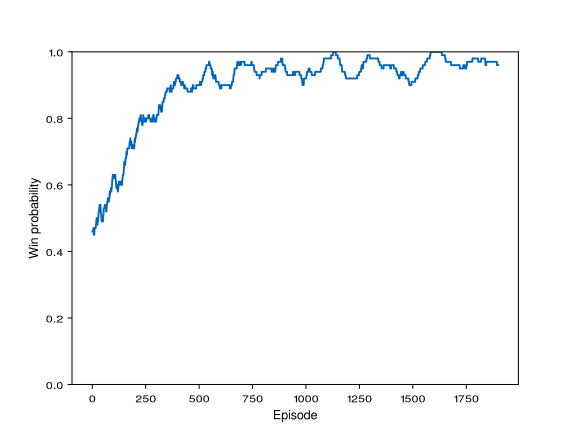
The graph of the singleplayer Catch training looks a lot better. It shows the win probability per episode by utilizing a moving average calculation. The agent improves it's strategy trying to maximise rewards and, after around 1000 episodes, finds a near-perfect policy to catch all the objects.
While graphs are nice, I'm sure you want to see the agents in action, so here we go:
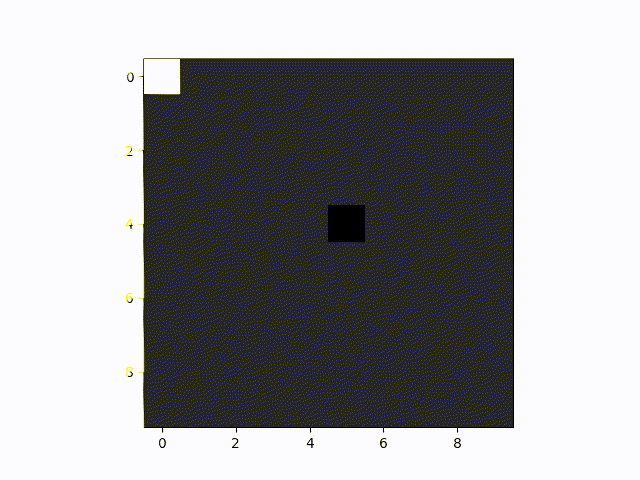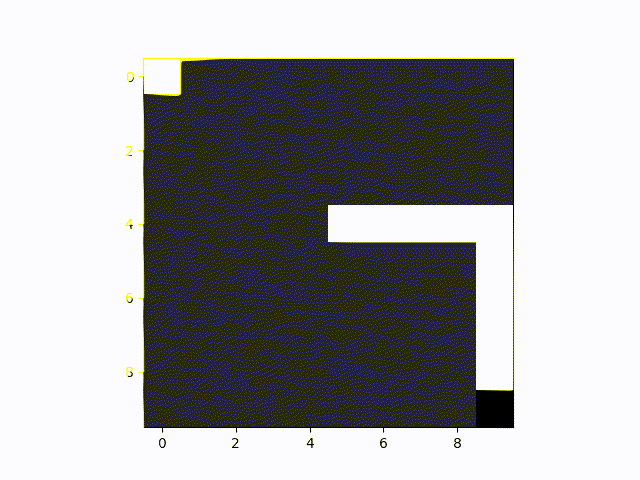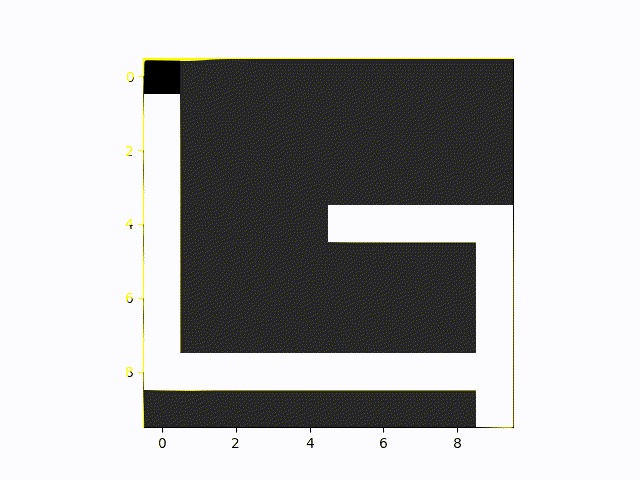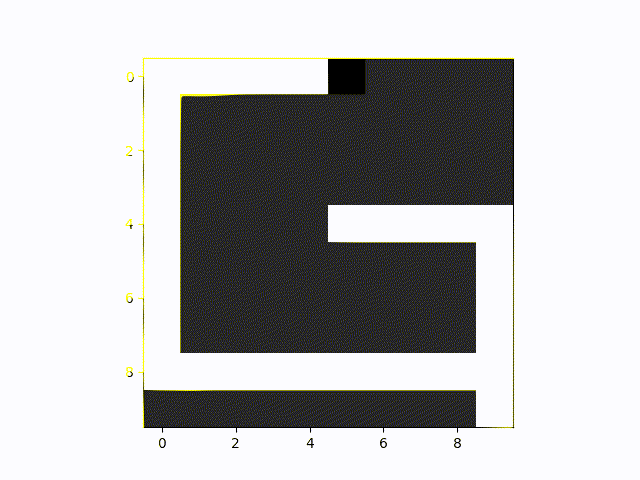
This is a neural network playing the resource collection game. As we saw earlier in the graph, it does not manage to learn a perfect policy. This can be seen here when the player remains still for some frames instead of moving on and collecting more blocks.
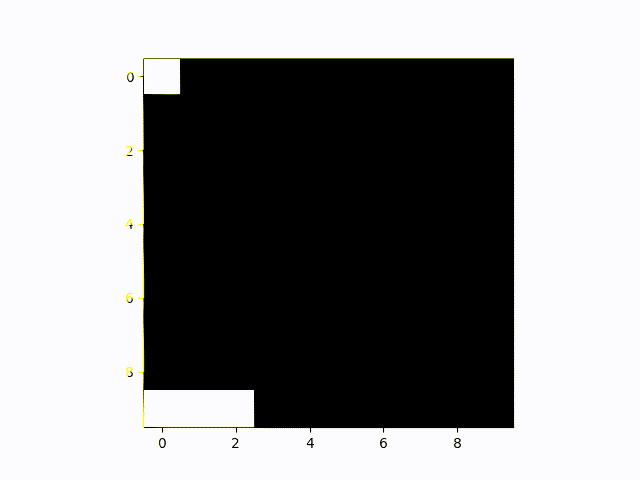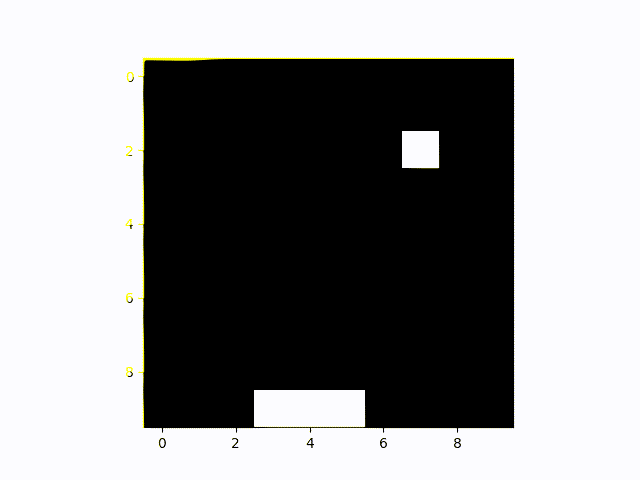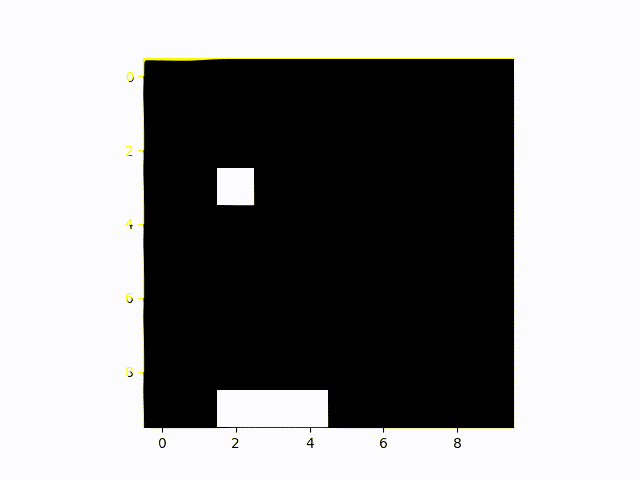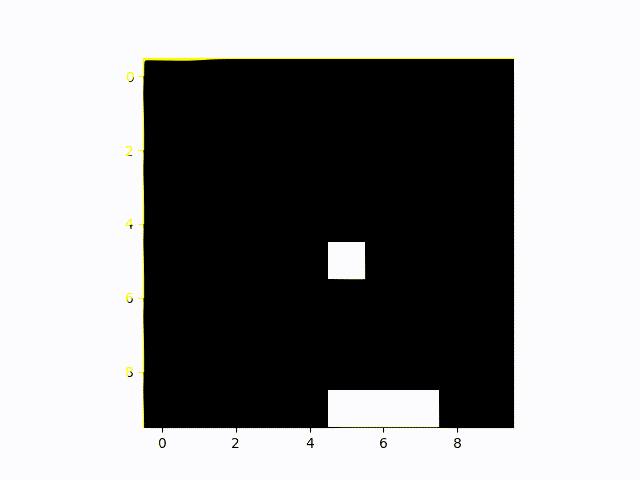
The Artificial Intelligence agent playing Catch here does a really good job. You can see it quickly moving around as soon as the falling object shows up to catch all of them.
Now to the interesting part: multiplayer gaming. Again, we start with some graphs showing the runs with the most successful training hyperparameters. Each of the players is represented by a totally independent neural network with its own rewards, loss function, hyperparameters, and learning algorithm. The only way the networks see what the other player is doing is by observing changes in the incoming video frames.
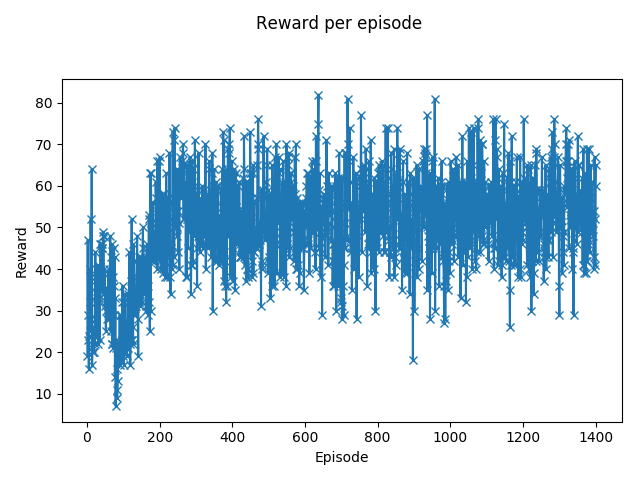
In the resource collection game, each agent receives a reward when a resource is collected, no matter which player collects it. This is necessary to facilitate cooperation and stop the agents from competing for the resources. The graph plots the combined rewards. While it looks similar (or rather: similarly bad) to the singleplayer one, we can see that it stabilizes at a value of around 55. This means that, apparently, the agents did not learn to avoid areas where the other player had already collected the resources.
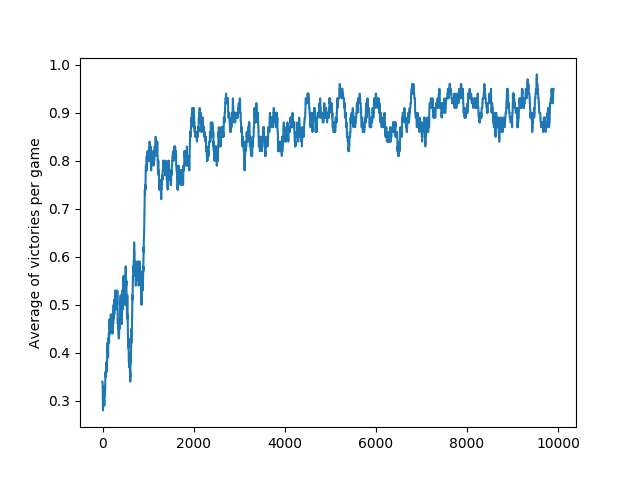
Multiplayer Catch worked a lot better. As you can see, the average victory rate rises quickly and converges to 100%, meaning that the agents figured out how to divide the two falling objects between them and end up catching both. Note that an episode only counts as a win (and both players only get a reward) if both objects are caught.
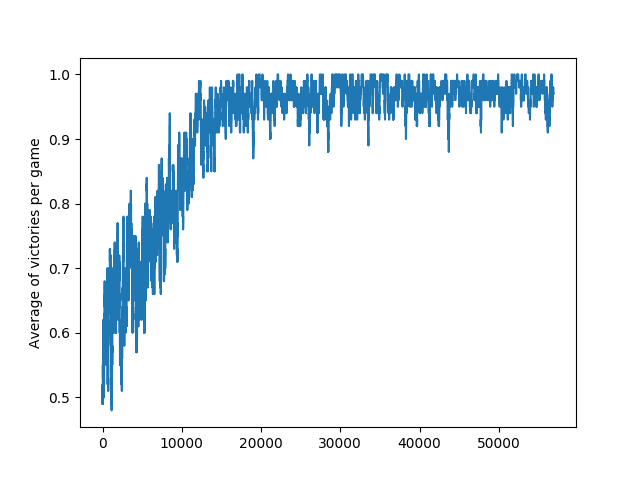
As a variant, I tried to replace one of the neural network agents with a "simulated human" player. In each round, one of the two falling objects is randomly chosen, the human player positions itself directly underneath it and stops moving for the remaining time. This was to test whether the AI agent can quickly figure out which object is left to catch. As you can see, this scenario took the agent a bit longer to figure out (mind the different x-axis scaling), but eventually also stabilized at 100% performance.
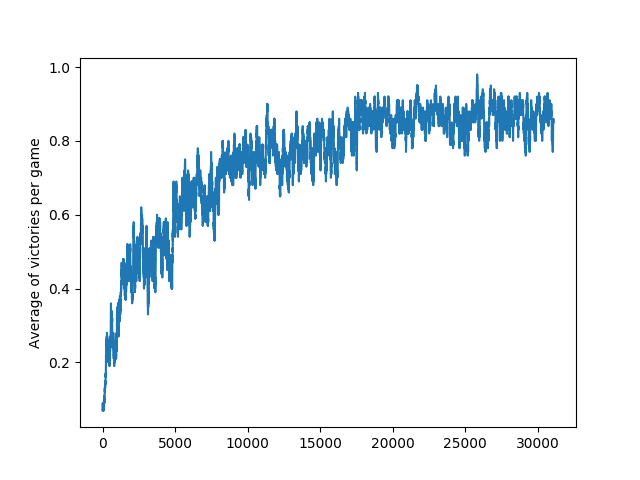
Finally, this graph documents the average win rate in Coopmobile Catch. Even in this more complex cooperative environment, the agents constantly improved their joint performance and manage to learn a strategy in which they catch, on average, 85% of the falling objects. At this point, I might add that even for 2 human players, acing the performance was quite tricky.
Again, let's have a more visual look at the results and watch some AI agents play my cooperative games.
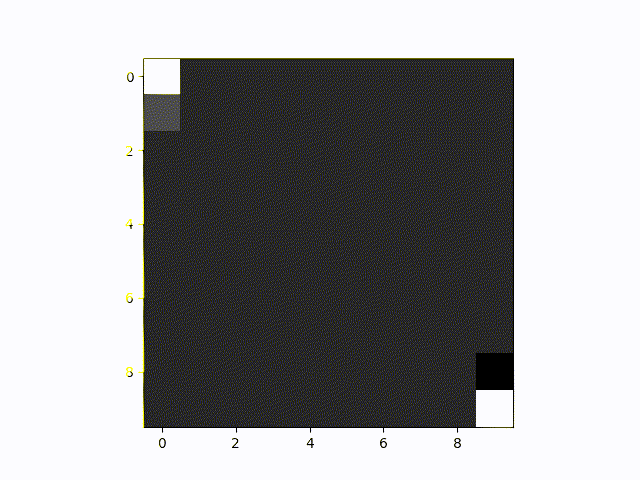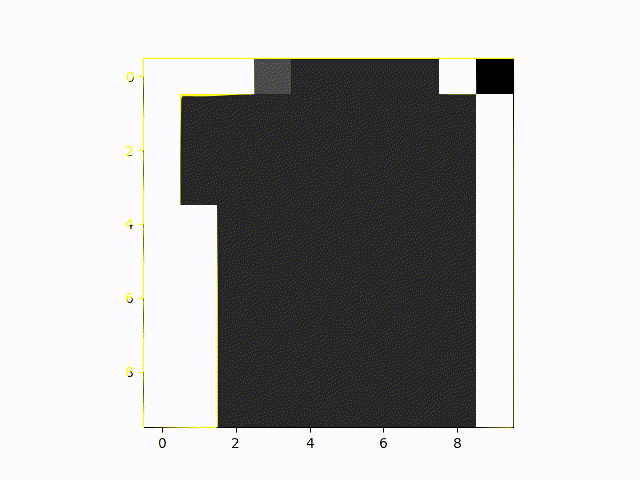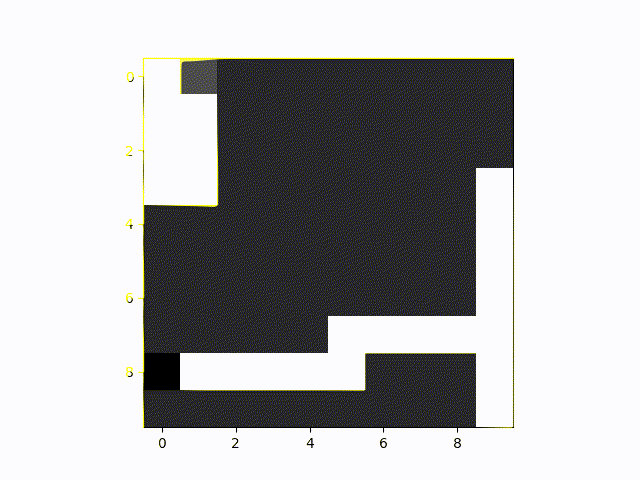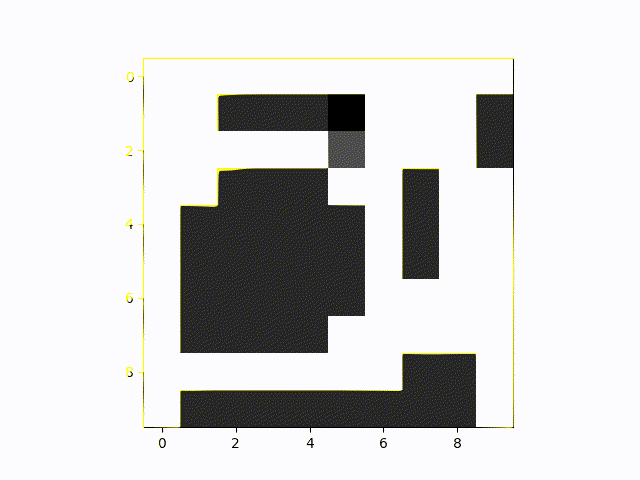
As you can see, the two AI agents in the resource collection game don't do terribly, but they also run into the wall a lot and walk into areas where the other player has already collected the blocks.
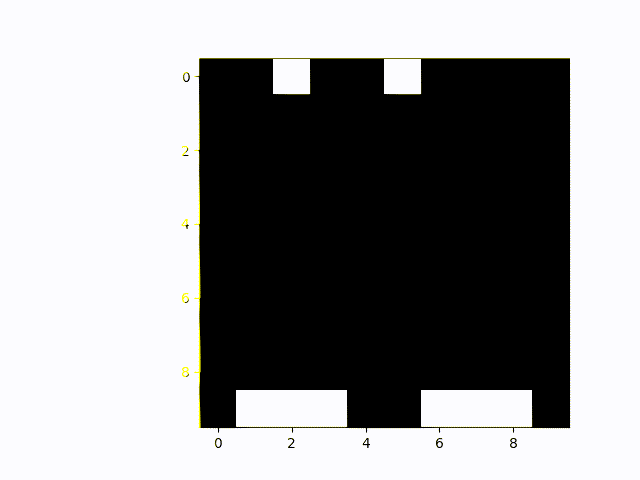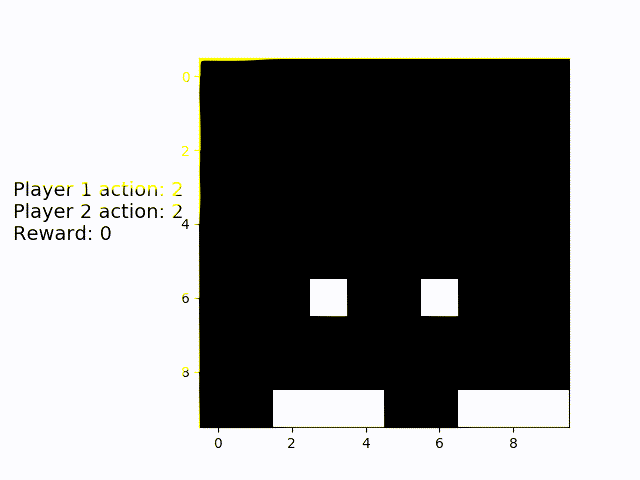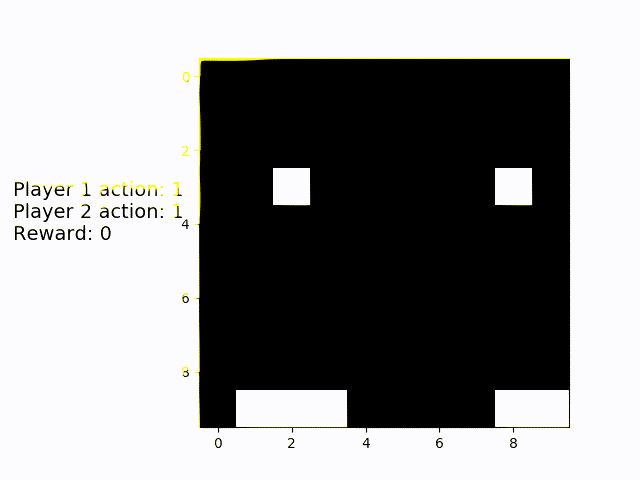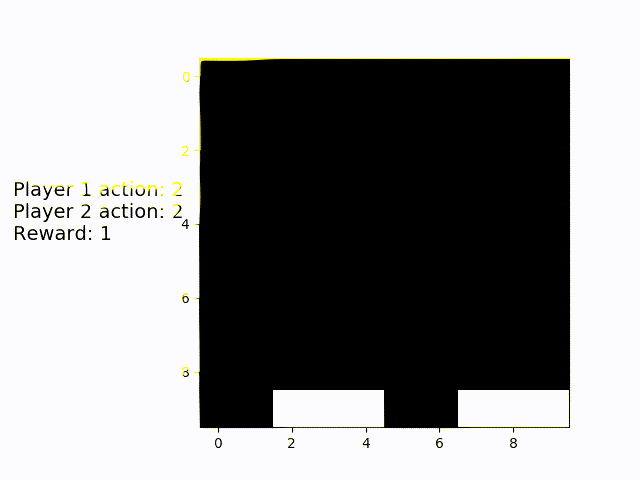
This is multiplayer Catch. You can see that the agents have figured out a good way to almost always catch both objects: Whoever is on the right catches the right object and vice versa.
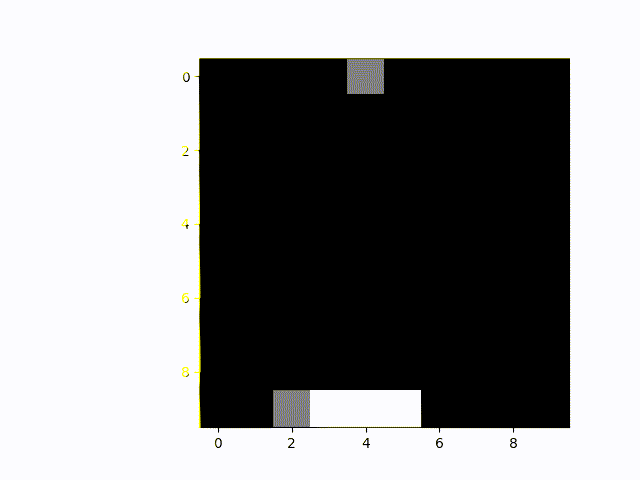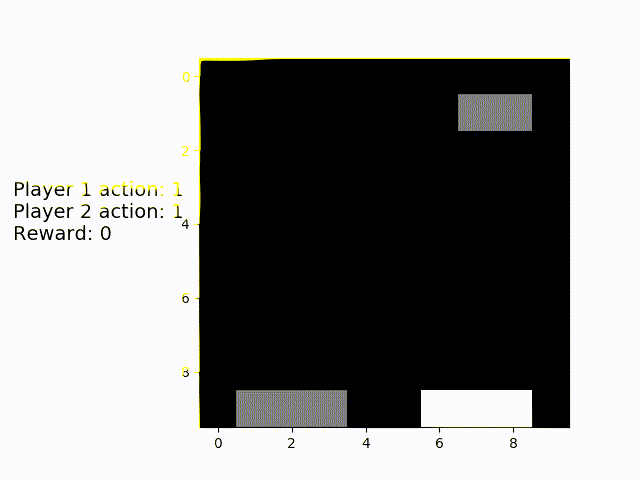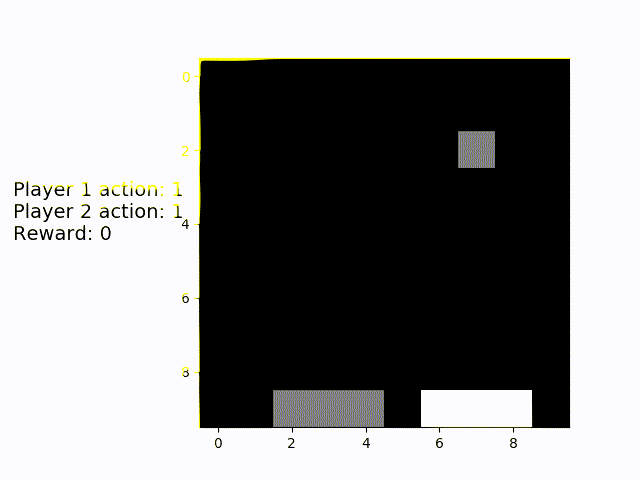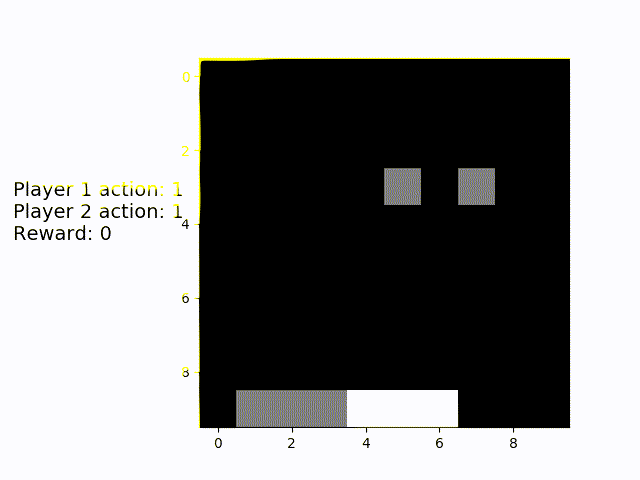
Next up is the "simulated human" multiplayer variant. The white platform is always placed underneath a random object, the grey AI player has to catch the other one. We can see that is has to move about a lot more, but also manages to catch the remaining objects in almost 100% of the games.
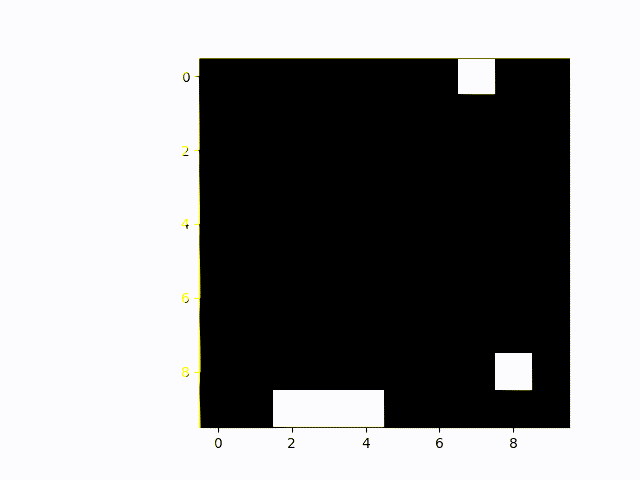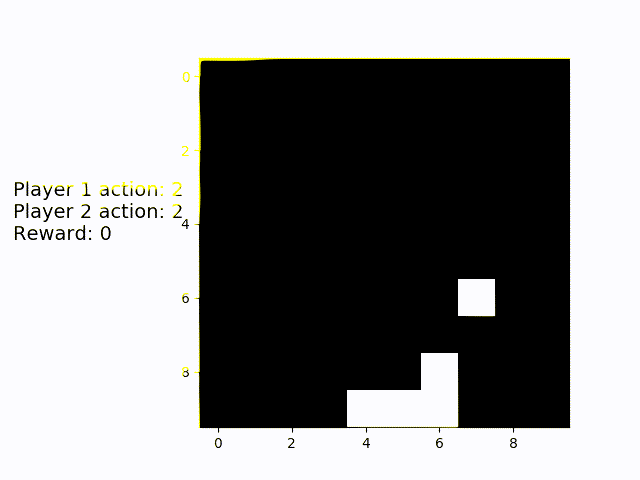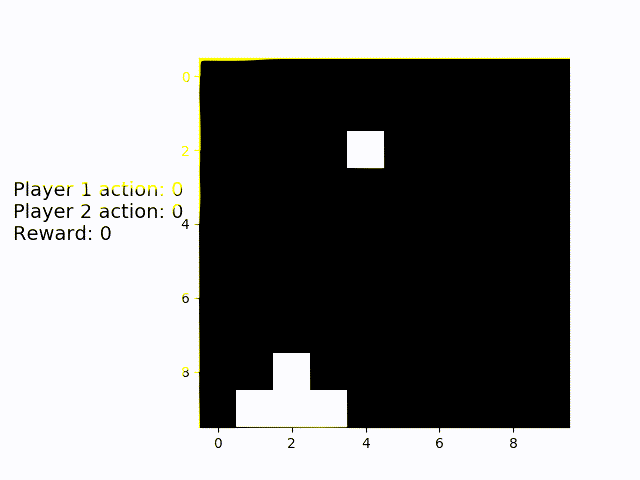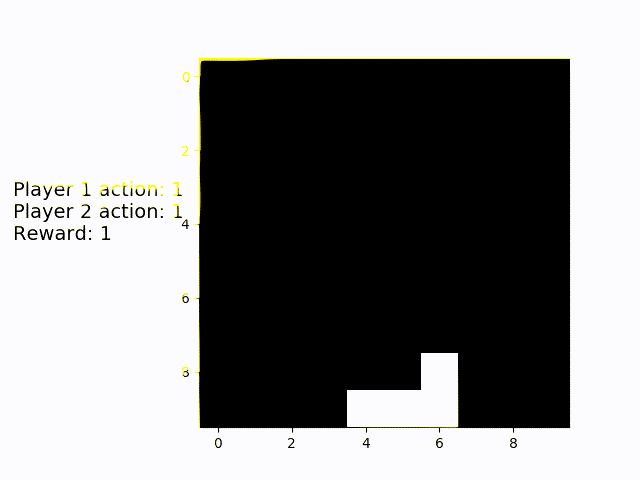
Finally, the game with the most intense need for cooperation: Coopmobile Catch. Even here, the two agens align themselves perfectly with the object and catch nearly all falling blocks.
All in all, I was pretty impressed by how well the two agents learned to solve the cooperative tasks. While the
cooperation did not work well for the more complex game of resource collection, all variants of Catch were mastered
by the agents.
The complex game, however, didn't even work well in singleplayer mode, so I have to assume that I just did not find
the fitting network architecture or hyperparameters. In the case of multiplayer Catch, and especially the even more
demanding version
Coopmobile Catch, the neural network players developed cooperative strategies to achieve their shared goal of
gaining points.
My personal conclusion from this is that, indeed, artificial intelligence agents can learn cooperative
behaviour, similar to the one of humans, from scratch. For now, I'll leave the technical and philosophical
consequences of this to you.
This blogpost only scratches the surface of my research and results. If I got you interested, feel free to read my full publication on ResearchGate.

Lars Carius
Tech entrepreneur with a passion for computer vision, augmented reality, machine learning, and simulation engineering with a Master's degree in "Robotics, Cognition, Intelligence" from the Technical University of Munich.