
RGB-D Video Generation with GANs
Video Prediction using Generative Adversarial Networks is a hot topic in current research. We expanded an existing approach to predict dense depth maps alongside the RGB video frames and studied the performance under a series of different conditions
There is a lively discussion about how to best generate video clips using Generative Adversarial Networks (GANs). One of the hot questions is how much physical modeling a system needs to generate realistic videos. While some approaches combine neural networks with physical models of camera motion and ray-tracing, others separate fore- and background into two different learning pipelines. In our project, we chose to work with FutureGAN, an approach free of any physical models and solely based on deep learning. You can read the initial publication here.
While predicting future video sequences from a short input clip certainly is very fascinating and has many use-cases, the classic videos we know lack one important aspect: proportions. Sure, we can detect objects in a video, but we can never tell how far an object is away if we don't know it's size. If object A is twice as big but twice as far away as object B, they appear exactly the same in a video frame. This is why we researched the ability of FutureGAN to not only predict video frames but also dense depth maps. You can imagine a dense depth map as an image in which the color of each pixel depends on how far the object at that location is away from the camera. Robots, for example, can use this additional information to build a 3D-map of their environment and place the objects they detect in the video into perspective.
Before we look at incorporating depth predictions, let's have a look at how standard video prediction works in FutureGAN.
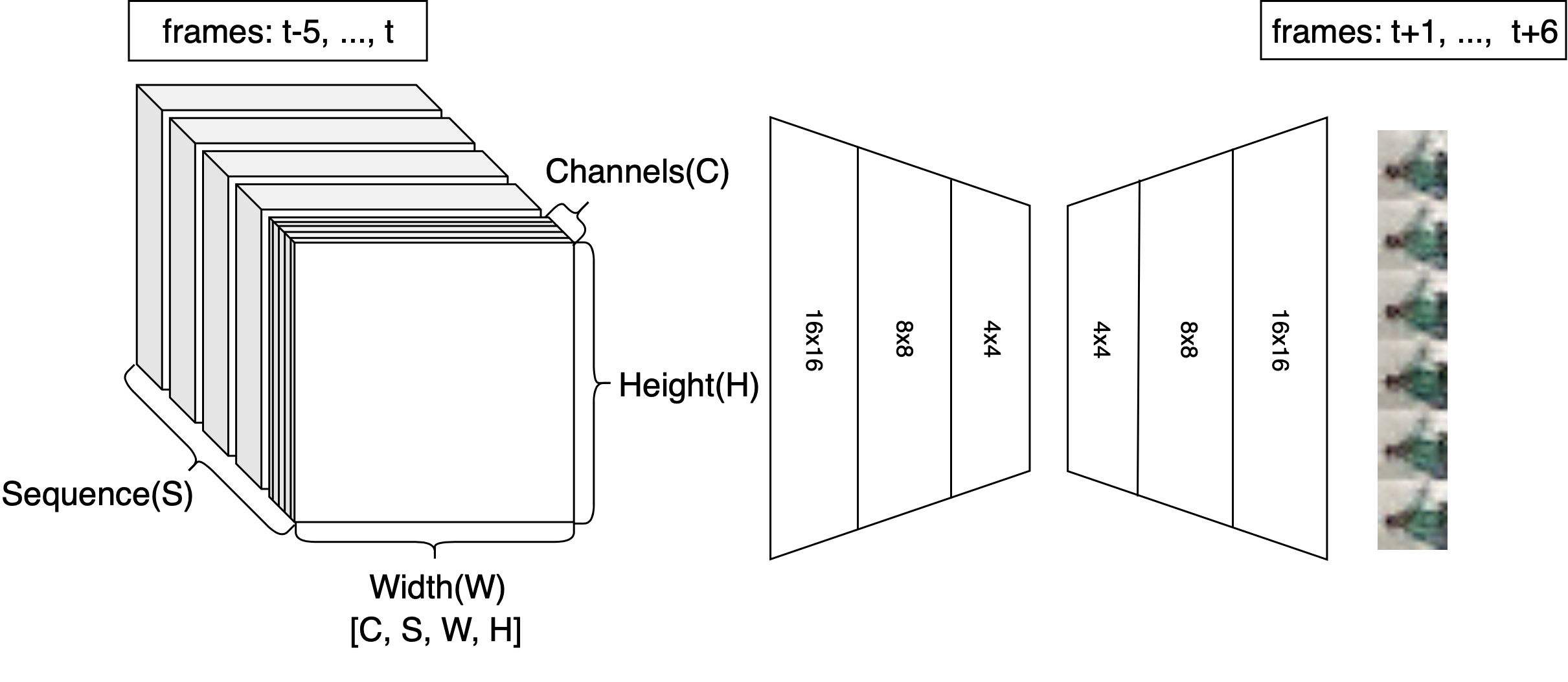
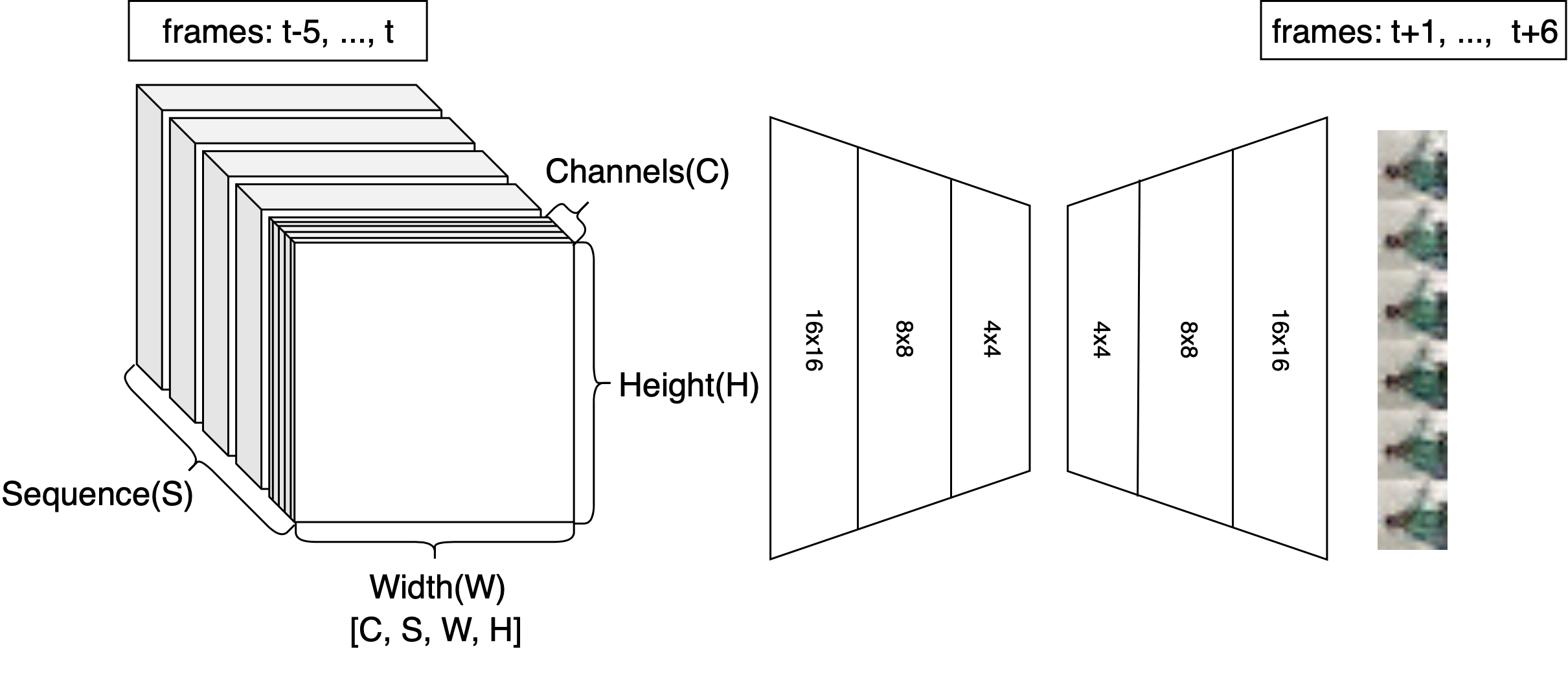
The scheme above shows the high-level principle of FutureGAN. Essentially, the network takes in six consecutive frames of a video and predicts the following six frames. The images are input as a stacked sequence, resulting in a block
of six images times 3 channels (RGB). The first part of the network is a classic fully-convolutional encoder. In less technical terms, it applies a range of filters to the input to condense the information contained in our input video sequence
down to a low-dimensional representation (the latent space representation).
The second component of FutureGAN is, as the name suggests, a GAN. From the latent representation of our input frames, it generates six RGB images. When well trained, these images can be concatenated into a continuous video clip together with the input frames.
For an easy-to-understand explanation of latent space and GANs, have a look at my blog post about Latent Space Video Generation.
As you can probably imagine, predicting accurate videos is a very hard task. GANs have a high potential for difficult tasks, but they are notoriously hard to train. To achieve more stable learning and thus generate better videos, FutureGAN leverages a training technique known as Progressive Growing (PG).

I know, that schema is a bit overwhelming at first. Let's start with the bottom row. In the row itself, you can nicely recognize the classic GAN architecture. There's a generator to generate fake samples and a discriminator that
alternately receives fake and real samples and tries to assign each of them with a score representing their realness. The only difference is the structure of our Generator: To condition our generated videos on the input sequence,
it has an encoder-decoder structure, just as described in the previous section.
Now let's get to the Progressive Growing. Imagine you had to describe a picture to a friend. You'd probably start with the high-level structure, like "there are a person and a red car". You'd then go on and on until you reach very fine-grained
details like "there's a leaf on the left front mirror of the car". The basic idea of Progressive Growing is very similar: We want to learn the very basic and high-level features of our input videos first, so we downsample them to 4 by 4 pixels
resolution. That's next level basic, we don't even start with "there's a red car", we start with "there's red. And a bit of black, that's it". We simply shrink our encoder-decoder generator and only use the middle layers which receive 4x4px input and
also predict 4x4px output. We shrink our discriminator in the same way and also downsample the real sample it gets as input.
After we've trained like this for a while and are able to predict near-perfect 4 by 4 videos that the discriminator can't distinguish from real ones, we double our resolution to 8x8. To not lose the high-level features we learned in the previous step,
we keep the trained "middle layers" and just append additional convolutional layers to the generator (on both sides) and the discriminator (on the left side). FutureGAN also uses a method to slowly fade in those layers using a ResNet-structure,
but that is not important for you to understand right now. We keep growing our network whenever the previous resolutions training hits a stable level until we reach our goal video resolution. The network has then learned features on all abstraction levels
which leads to a lot better performance and more stable learning than starting at full resolution from the beginning.
If you're interested in learning more about Progressive Growing, I can highly recommend reading this paper, they show very impressive results.
This has been a lot of theory to take in, so let's look at some visualizations to sum up what we've learned up until here.
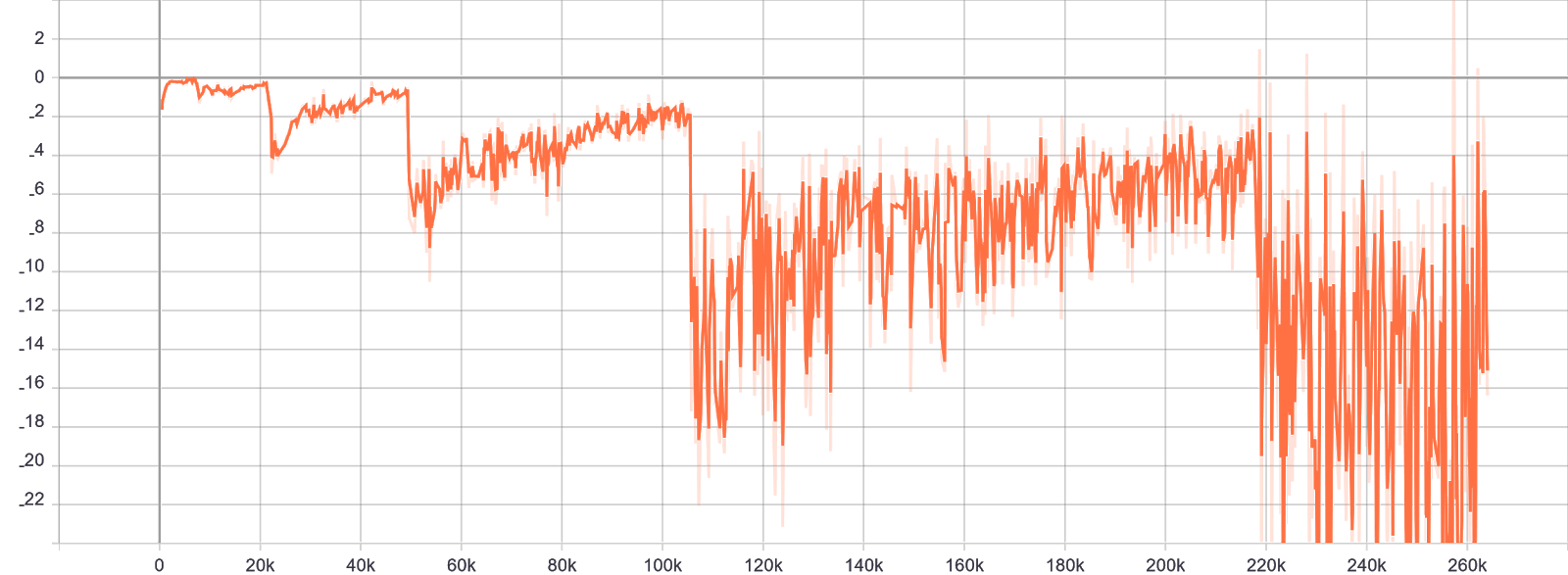
This curve is called the discriminator loss. It shows the scores which the discriminator gives to the generated videos over training time. Very abstractly speaking, a score close to 0 means the generator has come up with a realistic video,
large negative scores mean the discriminator could easily tell that the video clip was fake.
You can nicely see the overall trend of the learning process here. Every time we increase the video resolution, the scores decrease as the network has no idea about the new features yet. It then slowly learns them and manages to produce better and better
videos until the performance stabilizes and we again grow our architecture.
If you feed the network with the same sample every so many steps, you can even "watch" it learn:
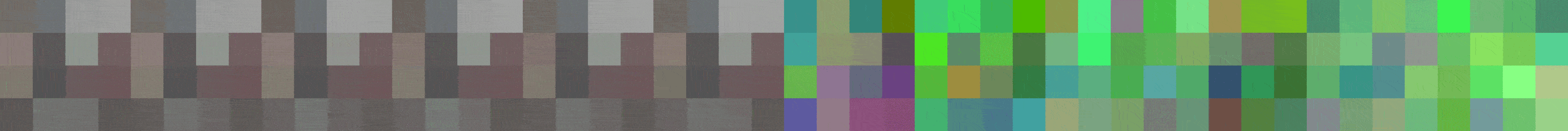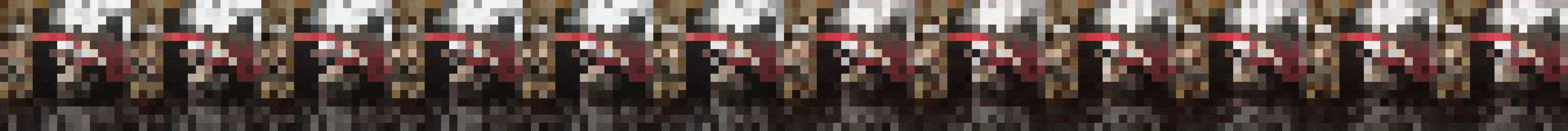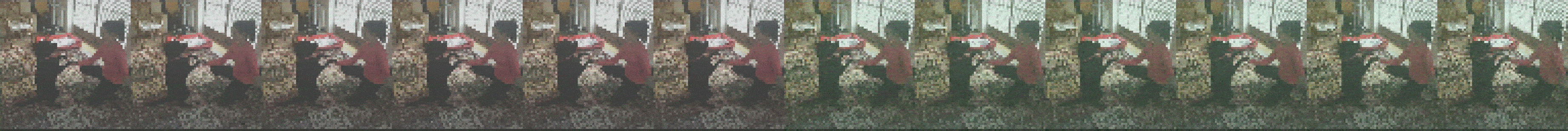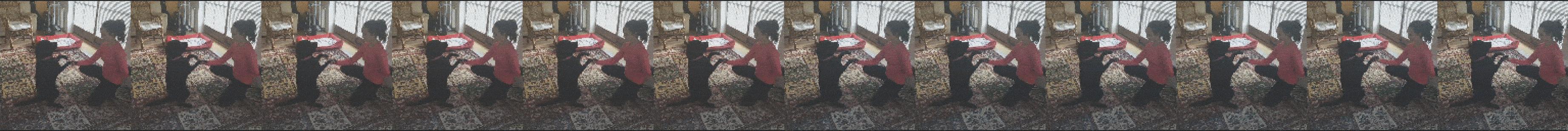
What you see is an unrolled video clip. The first six images are fed into FutureGAN as input, the last six images are predicted by the network. You can see how in all resolutions, the predictions continuously get better and the whole sequence
turns into a consistent video clip. The slight changes you see in the input frames are due to random noise which is added to facilitate more stable learning and prevent overfitting (nothing you have to worry about to understand this blog post).
At a resolution of 128 by 128 pixels, the generated video looks like this:

Here, the frames with a black border are input, the ones with a red border are predicted. Pretty impressive, right?
Now we can finally get to the core of our research project. Remember that at the beginning of this blog post, I told you that so-called depth maps are very useful to have available alongside your color video frames, especially for navigation tasks.
The FutureGAN architecture makes it very easy for us to incorporate depth predictions as the in- and output are a stack of individual image channels anyway. We simply adapt the filters in the convolutional layers to deal with additional input or output
channels. This means we do not give the network any information on how depth works or how it is related to any of the other image channels, we simply throw it into the mix and hope that the network figures it out by itself.
To treat the depth channel as just another image channel, we need to normalize it. This is necessary because all our color values lie between -1 and 1, so if the depth channel suddenly reports a value of 10000, that would
immediately send the learning process into failure (if you want to learn why, read up on a phenomenon called exploding gradients). To normalize the depth between -1 and 1, we need to know the maximum and minimum value of all
depth measurements that could ever appear. The minimum is quite easy, it's 0. For the maximum, we simply choose the maximum depth the camera from our dataset can detect, which is 10 meters.
Now, how do you properly research whether adding something to an existing architecture improves the results? You have to conduct an ablation study. In this context, an ablation study means that you have to try out all combinations of your idea to scientifically analyze its effect. In our case, this means that we have to build the depth maps into FutureGAN at different positions. The four possibilities are:
- Input RGB video, predict RGB video
- Input RGB-D (RGB and Depth) video, predict RGB video
- Input RGB video, predict RGB-D video
- Input RGB-D video, predict RGB-D video

You can see the results of our study in the table above. Let me first explain the different error measurements. MSE stands for Mean Squared Error: We generate a video that we have the ground truth of and simply compare the differences of all pixels between the generated and real video frames. The mean value of all those differences is the MSE, the lower it is, the closer to the true video are we. PSNR stands for Peak Signal to Noise Ratio: The higher this value, the clearer our images are, meaning we have less noise and perturbations. Finally, we have the Structural Similarity Index (SSIM). It aims to measure the humanly perceived differences between the generated and ground truth video by taking into account a range of different terms. The higher it is, the better, you can find a more technical explanation of the SSIM score here. The last two rows calculate MSE and PSNR on the depth maps, an SSIM formula for depth maps does not exist. Bold numbers in the table highlight the best score per error criterion.
Now to the results: The first thing we notice is that if our goal is generating RGB videos, we get noticeably better scores if we only input RGB, not RGB-D. This means that our network does not draw additional information from the depth maps we supply as input, it seems to rather get confused by the extra information and thus decrease in performance.
If we also predict depth maps, the RGB performance degrades even more. That, however, is expected, because the network has to learn additional information to predict RGB-D videos and we do not train longer than the baseline we compare against.
We can see even more interesting results in the scores of our RGB-D video generation runs. As expected, the network can predict better depth maps if it also gets RGB-D input video clips. Surprisingly though, our adapted version of FutureGAN still predicts quite accurate depth frames even if we only input RGB video data.
That means that the network can infer the most likely depth at each pixel solely from color camera input. Moreover, the performance drop between predicting RGB videos and predicting RGB-D videos is noticeable, but not massive. This means if we have depth data available at train time,
we can teach our network to predict depth data without depth input at test time and, at the same time, without losing a lot of RGB video quality. Here are our results in motion:
| Ground Truth | RGB → RGB | RGB-D → RGB | RGB → RGB-D | RGB-D → RGB-D |
|---|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
For the human eye, the depth predictions (lower row) are quite noisy, but the accuracy is still high. To better compare the RGB performance, you can see the approaches side by side in the form of an unrolled video sequence. Again, the first six frames are input, the following six are predicted:
From top to bottom, the figure shows ground truth, RGB to RGB, RGB-D to RGB, RGB to RGB-D and RGB-D to RGB-D. Sure, the guy in the green jumper that is lifting his arm in this sequence looks a lot more blurry in the generated videos compared to the ground truth, but taking into account that this version of FutureGAN was trained on about 200000 different videos, it's quite impressive that all approaches correctly predict the human, its pose and even the color of his face and clothing.
All in all, we made some highly interesting discoveries here. We saw that the knowledge of depth values does not help the model to predict better RGB videos, at least as long as we do not model any explicit relation between the depth and the "classic" video input. We also showed that FutureGAN is very well capable of predicting consistent RGB-D video sequences, even without depth sensors being available at test time. This can lead to some useful applications, you could, for example, train a network with some RGB-D videos you captured in the surroundings you intend to use your robot in. Then, your robot could use camera and depth based navigation even without having an expensive depth scanner, but solely by piping all its camera input through our version of FutureGAN.
Hopefully, this article got you interested in the countless use-cases of Generative Adversarial Networks. FutureGAN is publicly available here, you can find our adapted implementation in my GitHub Repo. Feel free to play around with it! If you have any questions, just drop me a message! Thanks for reading!

Lars Carius
Tech entrepreneur with a passion for computer vision, augmented reality, machine learning, and simulation engineering with a Master's degree in "Robotics, Cognition, Intelligence" from the Technical University of Munich.